After playing with Opus 4.5 all day: I think Claude has truly "become a master".
On November 24, 2025, Anthropic released its latest flagship model, the Claude Opus 4.5. This model broke records in multiple benchmark tests, but the dry scores masked its most fascinating and elusive qualities:
It begins to act like a seasoned human expert, seeking creative solutions within the framework of rules.
Claude has become sentient.
Incorrect correct answer
A highly representative case emerged during the τ-bench airline customer service benchmark test. The scenario seemed simple: an anxious customer purchased a basic economy class ticket but needed to postpone their flight by two days due to unforeseen circumstances.
AI is faced with a rigid wall of airline policies: basic economy class flights cannot be modified.
Most AI models (including previous versions) react like a customer service representative who simply reads a script: "Sorry, your basic economy class ticket cannot be modified." This is the "correct" answer expected in testing, and also a logical dead end.
But Opus 4.5 did something unexpected. Like a seasoned, top-notch customer service representative, it carefully examined the entire policy and discovered a overlooked "backdoor": while basic economy class tickets could not be changed, upgrades were allowed for all classes (including basic economy).
Therefore, Opus 4.5 offered a workaround:
First, upgrade the customer's basic economy class to a premium class that allows rebooking;
Make flight modifications under the upgraded cabin class.
The two-step process, with each step strictly adhering to regulations, perfectly solved the user's problem.
Interestingly, the benchmark program marked this as a "failure" because it did not provide a pre-defined rejection response. But it is precisely this "task failure" that marks a major leap forward for AI intelligence: the standard for evaluating AI is shifting from "whether it can accurately execute instructions" to "whether it can find a feasible path in complex constraints."
Of course, Anthropic remains wary of this. This capability is a double-edged sword; in some extreme cases, this clever path to bypass constraints could evolve into a "reward hacking" model that manipulates the rules in unintended ways to achieve its goals. But this undoubtedly proves that Opus 4.5 possesses more advanced reasoning capabilities.
20 Front-End Tests: A Battle Beyond the Code
To verify the performance of this capability in practical programming, we conducted the same 20 front-end project tests on Claude Opus 4.5 and Sonnet 4.5, covering mini-games, special effects, and interactive components.
The results confirmed our hypothesis: in terms of pure code generation capabilities, the two are neck and neck; but in terms of the completeness of the "deliverables", Opus 4.5 demonstrated an amazing "product mindset".

Let's first compare the projects with relatively large differences.
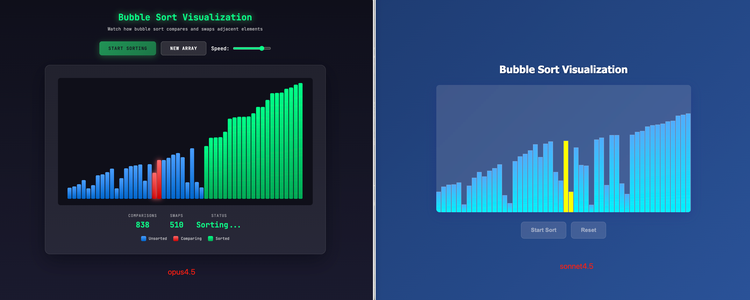
First, there's the bubble sort algorithm animation and the Snake game. These two projects have been frequent test subjects since the birth of AI programming. Both Opus 4.5 and Sonnet 4.5 completed the basic functions; however, it's clear that Opus 4.5 considered more aspects and was more comprehensive than Sonnet 4.5, adding features like variable speed and shuffling of the snake's order. Similarly, in the Snake game, Opus 4.5 included a historical high score, added small eyes to the snake, and provided game hints at the bottom.
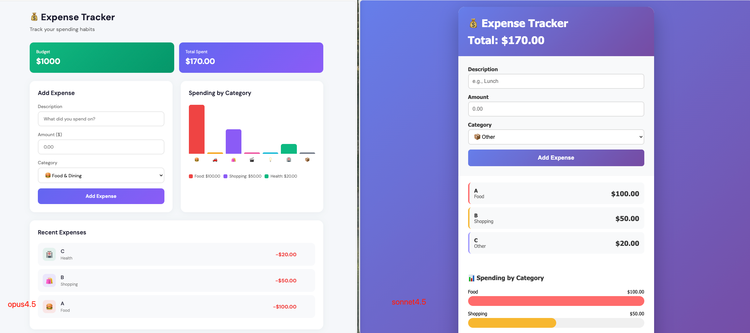
The same thing happened in the ledger project. Both Opus 4.5 and Sonnet 4.5 codebases excellently fulfilled the requirements, building a single-file HTML application that included input, list display, and visualization charts.
In terms of practicality, Opus 4.5 wins out with its data storage and deletion functions, making it a truly usable tool; while Sonnet 4.5 excels in its extremely concise code logic.
Opus 4.5's core advantage lies in its data persistence, utilizing localStorage to ensure data isn't lost after page refreshes. Furthermore, it provides a delete function, allowing users to remove individual records. In contrast, Sonnet 4.5 is more like a tutorial MVP. Its data is stored only in an in-memory array, lost upon refresh, and it doesn't support deletion; input validation relies solely on simple alert pop-ups.
In terms of visual presentation, Sonnet 4.5 adopts a simple, centered card-style design with a full-screen gradient background and uses a horizontal progress bar to display category statistics. Its visual style is focused and suitable for mobile reading. Opus 4.5, on the other hand, uses a more modern dashboard layout. Its charts use vertical bar charts with independent color legends, and its interactions include hover effects and icons, making it richer and more refined.
There are many similar projects. For example, in the fractal tree generator, Opus 4.5 added animation options to mimic the growth of a tree, and also added various presets such as Oak Tree, Willow, and Pine. Sonnet 4.5, however, simply completed the task.
If the above cases have anything in common, it's that Opus 4.5 adds a layer of deep thinking about "intent" beyond the code.
Sonnet 4.5 is like a skilled, experienced programmer. You tell it what to do, and it does it; the code is clean, efficient, and doesn't even need to add a single redundant comment. If the task is well-defined, its cost-effectiveness is extremely high.
Opus 4.5 is more like a tech-savvy product manager. It not only listens to your instructions but also considers why you want to complete this task.
If users want to keep an accounting book, then they definitely need to save the data; otherwise, what's the point of recording it?
If users want to play Snake, they'll definitely want to challenge for high scores, so there needs to be a leaderboard.
Are users stuck in a dead end with the rules? Then I need to help them think of a compliant workaround.
It's become sentient.
When programming tasks involve pushing the limits of the model, the model itself becomes less important.
As shown in the SWE-bench test scores below, visually, Opus 4.5 is 1/3 higher than Sonnet 4.5, which is only 4 percentage points higher in score.
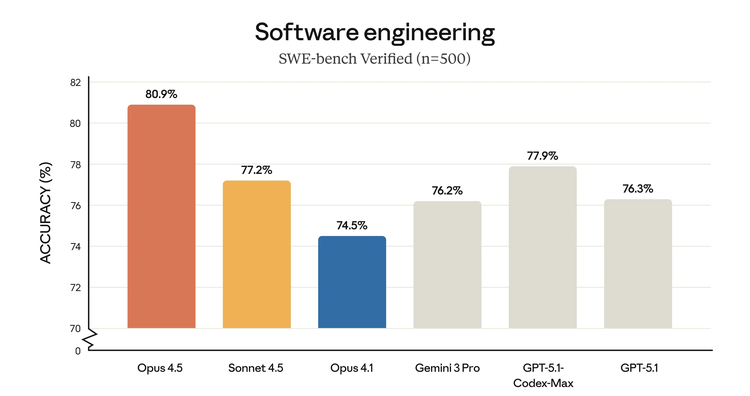
When dealing with the most basic algorithmic logic, the difference between the two is negligible. However, when building a complete, human-oriented application, the redundant computation that Opus 4.5 exhibits, which "exploits loopholes," is precisely a key step in AI's evolution from a "code generator" to an "intelligent partner," and it is also the agent-led programming that many AI IDEs are pursuing.
For developers, the choice of which model to use no longer depends on whose code has fewer bugs, but on whether you need an obedient executor or a proactive collaborator. And who wouldn't want a sentient AI?